Google, yaklaşık 30 yıl önce, 1998’de arama motoru serüvenine başladı. Başlangıçta Backrub olarak bilinen ve Stanford kampüsünde faaliyet gösteren şirketin ilk sunucusu 40 GB veri depolayabiliyordu ve Duplo bloklarından yapılmış bir kasaya yerleştirilmişti.
Daha sonra IBM ve Intel’den gelen destekle kurucular sunucuyu küçük bir raf sistemine yükseltti. Ancak 2025’te, Google araması artık tek bir veri merkezine bile sığmıyordu.
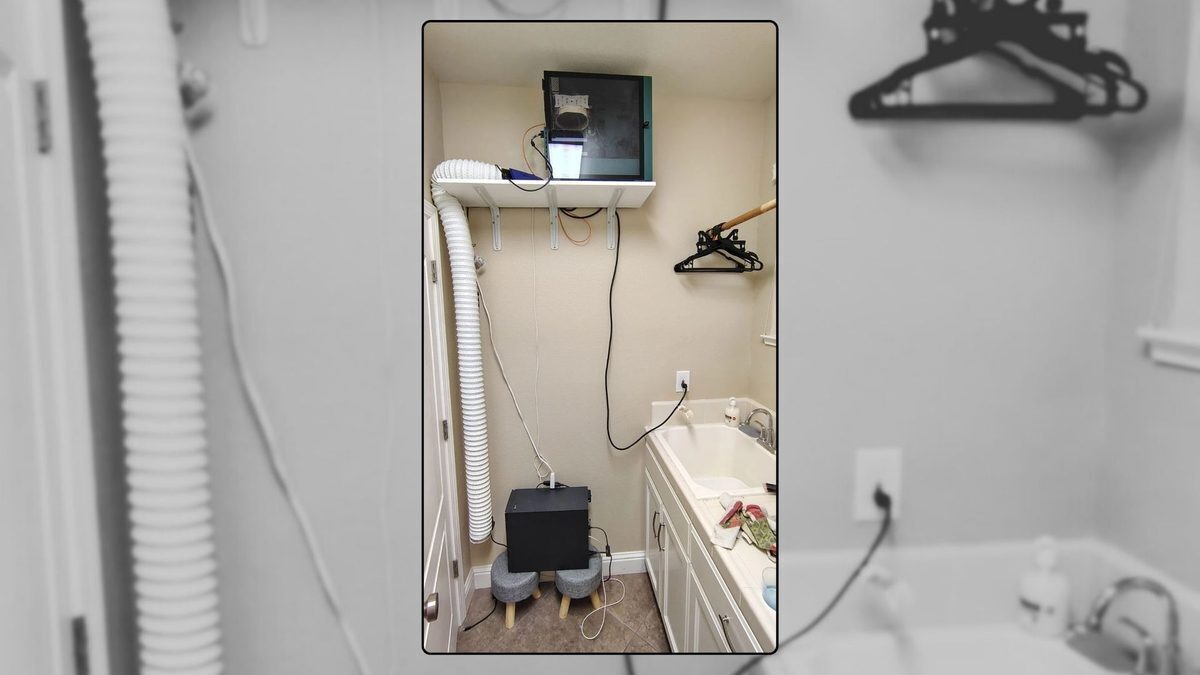
Ryan Pearce adlı geliştirici, akıllı kaynak kullanımı ve çok çalışmayla, orijinal Google sunucusuna yakın bir boyutta bir makine kurarak modern bir Google benzeri deneyim yarattı. Bunu kendi çamaşır odasında barındırıyor.
Pearce, geliştirdiği Searcha Page ve gizlilik odaklı Seek Ninja ile çalışıyor. Web sayfalarına bağlandığınızda, sunucu çamaşır odasında çalışıyor ama sonuçlardan bunu anlamak mümkün değil. Pearce, “Şu anda çamaşır odasında, 2000’de Google’ın sahip olduğundan daha fazla depolama alanına sahibim. Düşünmek bile çılgınca,” diyor.
Sunucunun çamaşır odasında olmasının nedeni hem ısı hem gürültü. Başlangıçta yatak odasında çalışıyordu, ama makine çok ısınınca uyumak zorlaşmıştı. Bu nedenle sunucu taşındı ve ağ kablosu için bir delik açıldı. Pearce, “Isı çok kötü değil, ama kapı uzun süre kapalı kalırsa sorun oluyor,” diyor.
Searcha Page ve Seek Ninja’nın performansı
Arama sonuçlarında küçük bir yavaşlama dışında, kalite yüksek. Bunun nedeni, iki platformun 2 milyar girdilik devasa bir veritabanı üzerine kurulu olması. Pearce, “Muhtemelen yarım yıl içinde 4 milyar belgeye ulaşmayı bekliyorum,” diyor.
Karşılaştırma: 1998’de Google’ın veritabanında 24 milyon sayfa vardı, 2020’de bu sayı 400 milyara ulaştı. 2 milyar sayfa günümüz standartlarına göre küçük bir damla olsa da, oldukça etkileyici bir başlangıç.
Yapay zekanın rolü
Pearce, “Yaptığım şey aslında klasik bir arama motoru, ancak anahtar kelime genişletmesi ve bağlam anlayışı için yapay zeka kullanıyorum,” diyor. Arama deneyiminde yapay zekayı devre dışı bırakmak zor olabilir, çünkü tersine görsel arama gibi araçlar tamamen yapay zekaya dayanıyor.
LLM’ler (büyük dil modelleri), Pearce’ın sistemini ölçeklendirmesinde kritik rol oynuyor. Kod tabanı şu an yaklaşık 150 bin satır, ve çoğu, LLM’ler tarafından üretilen özelliklerin geleneksel yöntemle uygulanması için yinelemeye tabi tutulmuş.
Donanım ve maliyet
Pearce’ın kurduğu sunucu güçlü bir CPU içeriyor: 32 çekirdekli AMD EPYC 7532. 2020’de maliyeti 3.000 dolar olan çip, Pearce’a eBay’den 200 dolara mal oldu. Sistem toplam 5.000 dolara mal oldu, bunun 3.000 doları depolamaya gitti.
Kendi sunucusunu kurarken Pearce, yükseltme arbitrajını kullandı: eski ama güçlü sunucuların fiyatı düşük olduğunda, uygun bütçeyle yüksek performans elde ediliyor. Bu yaklaşım, mini PC veya Raspberry Pi’lerden çok daha güçlü bir sistem kurmasını sağladı.
LLM ve küçük geliştiriciler
Pearce, Llama 3 modeli için SambaNova hizmetini kullanıyor. Bu sayede tek geliştirici bile güçlü yapay zekayı hızlı ve uygun maliyetli çalıştırabiliyor. Ayrıca, Common Crawl deposu sayesinde geniş bir açık web veri kümesine erişim sağladı.
Ancak bazı özellikler, örneğin vektör tabanlı ilişkisel arama, başlangıçta başarısız oldu. Pearce, “Muhtemelen beceri eksikliğimden kaynaklandı. Sonuçlar çok sanatsaldı,” diyor.
Wilson Lin gibi diğer geliştiriciler ise kendi veri ayrıştırma teknolojilerini kullanarak daha ucuz ve verimli bir sistem kurabiliyor. LLM’ler, her iki yaklaşımdaki önemli bir araç olarak öne çıkıyor.
Gelecek planları
Pearce, sunucusunu çamaşır odasında tutmaya devam edecek ama uzun vadede bir ortak veri merkezine taşımayı planlıyor. Reklam ve trafik gelirleri ile masrafları karşılamayı hedefliyor: “Planım, belirli bir trafik miktarını geçersem barındırılacağım. Sonsuza kadar çamaşır odasında kalmayacak,” diyor.


