Meta, Llama 4 ailesinin ilk modellerini tanıtarak kişiselleştirilmiş çok modlu yapay zeka deneyimleri geliştirmeyi mümkün kılacak yeni bir dönemi başlattı. Bu yeni modeller, metin ve görsel içerikleri doğal bir şekilde anlayabilen, uzun bağlamlarda çalışabilen ve gelişmiş çok modlu mimariler üzerine inşa edilmiş.
Llama 4 Scout ve Llama 4 Maverick adını taşıyan bu modeller, açık ağırlıklı (open-weight) ve çok modlu özellikleriyle, Meta’nın bugüne kadar sunduğu en güçlü modeller arasında yer alıyor.
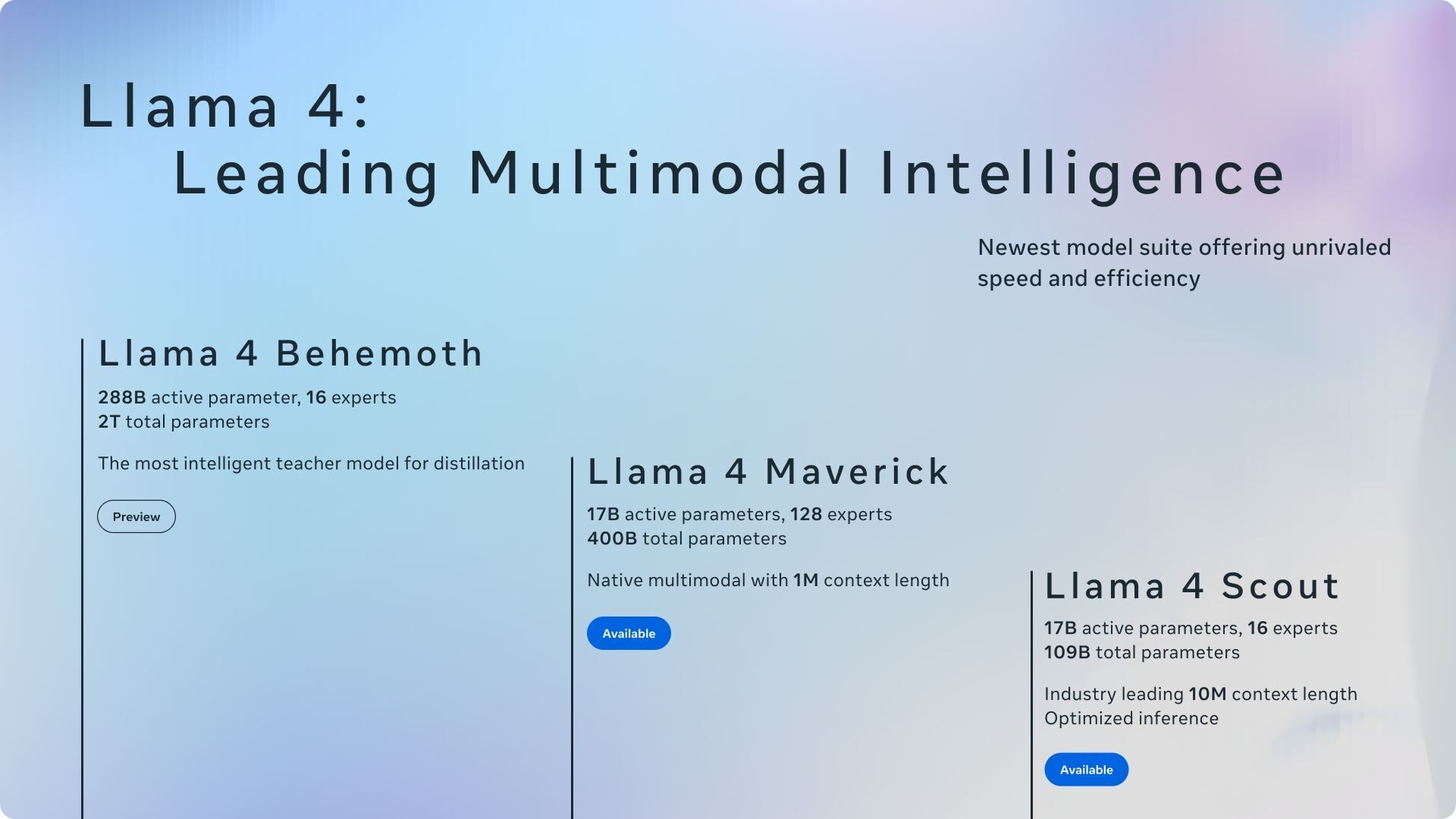
Ayrıca Llama 4 Behemoth isimli, hala eğitimi süren ve öğretici olarak kullanılan 2 trilyon parametreye yakın kapasitesiyle dünyanın en büyük ve en zeki modellerinden biri olma yolunda ilerleyen bir versiyon da tanıtıldı.
Yeni Llama 4 modelleri ne vaat ediyor?
Llama 4 Scout, 17 milyar aktif parametreye ve 16 uzman katmana sahip, kendi sınıfında dünyanın en iyi çok modlu modeli olarak tanıtıldı. Bu model, NVIDIA H100 GPU üzerinde çalışabiliyor ve 10 milyon token’lık bir bağlam penceresi (context window) sunarak çok uzun girdileri işleyebiliyor. Bu da Scout’un; Gemma 3, Gemini 2.0 Flash-Lite ve Mistral 3.1 gibi modellerin önüne geçmesini sağlıyor.
Diğer yandan Llama 4 Maverick, yine 17 milyar aktif parametreye sahip fakat 128 uzmandan oluşan bir yapıda tasarlandı. Bu yapı sayesinde GPT-4o ve Gemini 2.0 Flash gibi önde gelen modelleri çeşitli testlerde geride bırakıyor.
Ayrıca DeepSeek v3 gibi çok daha büyük modellerle karşılaştırılabilir akıl yürütme ve kodlama başarımı sunarken, daha az parametreyle bu kaliteyi yakalıyor. Maverick’in deneysel sohbet versiyonu LMArena testlerinde 1417 ELO puanı elde etmiş.

Tüm bu gelişmiş modellerin temelinde, Llama 4 Behemoth yer alıyor. Bu model, 288 milyar aktif parametreye ve 2 trilyona yakın toplam parametreye sahip. GPT-4.5, Claude Sonnet 3.7 ve Gemini 2.0 Pro gibi modelleri matematik, bilim ve teknik konulara odaklanan çeşitli sınavlarda geride bırakıyor. Henüz eğitimi tamamlanmayan Behemoth, Scout ve Maverick modellerine öğretici (teacher) model olarak hizmet veriyor.
Llama modellerindeki MoE mimarisi
Yeni Llama modelleri, “mixture-of-experts (MoE)” adı verilen uzman karışımı mimarisini kullanıyor. Bu mimaride her bir token, modelin yalnızca belirli bir bölümünü aktive ediyor. Böylece eğitim ve çıkarım (inference) süreçlerinde verimlilik artarken, kaliteyi korumak mümkün oluyor. Llama 4 Maverick, 400 milyar toplam parametreye sahip olmasına rağmen yalnızca 17 milyar aktif parametre kullanıyor. Bu sayede daha düşük maliyetleyüksek performans elde ediliyor. Modellerde yoğun (dense) ve uzman karışımı katmanlar dönüşümlü olarak yer alıyor.
Llama 4 mimarisi, doğuştan çok modlu (natively multimodal) olarak tasarlandı. Bu, metin ve görsel girdilerin erken aşamada (early fusion) birleştirilmesini ve tek bir model omurgasında işlenmesini sağlıyor. Bu sayede model, büyük miktarda etiketlenmemiş metin, görüntü ve video verisiyle ortak bir şekilde eğitilebiliyor. Görsel kodlayıcı kısmı, MetaCLIP baz alınarak geliştirildi ve Llama dil modeliyle birlikte eğitildi.
Eğitim süreci nasıl değiştirildi?
Modelin eğitim sürecinde Meta, “MetaP” adını verdiği yeni bir yöntem geliştirdi. Bu yöntem, her katman için öğrenme oranı gibi hiperparametreleri belirlerken tutarlılık sağlıyor. Llama 4, 200 dilde ön eğitim aldı ve Llama 3’e kıyasla 10 kat daha fazla çok dilli veriden beslendi. Eğitim sürecinde FP8 hassasiyetinde işlem yapılarak yüksek performans elde edildi. Toplamda 30 trilyonun üzerinde token ile eğitim gerçekleştirildi.
Model kalitesini daha da artırmak amacıyla “mid-training” adı verilen ara eğitim evresiyle yeni teknikler uygulandı. Uzun bağlam eğitimi özel veri kümeleriyle yapıldı ve Scout modelinde 10 milyon token’a kadar girdi işleyebilme özelliği geliştirildi.
Sonraki aşamada, modellerin sohbet ve görev çözme kabiliyetlerini artırmak için hafif denetimli ince ayar (SFT), çevrim içi pekiştirmeli öğrenme (online RL) ve doğrudan tercih optimizasyonu (DPO) gibi yöntemlerle post-training yapıldı. Özellikle SFT ve DPO’nun modelin keşfetme kabiliyetini kısıtlaması sorunu, kolay etiketli verilerin %50’sini çıkararak ve daha zor örneklerle eğitim yaparak aşıldı. Eğitim sürecinde modelin yalnızca orta ve zor seviye sorularla eğitilmesi sağlandı ve RL aşamasında bu yaklaşımla performansta ciddi artış sağlandı.

Peki ya güvenlik?
Meta, Llama 4 modellerini yalnızca güçlü yapmakla kalmayıp güvenlik konusunda da ciddi adımlar attı. Ön ve son eğitim aşamalarında veri filtreleme ve güvenlik politikaları uygulanırken, sistem düzeyinde “Llama Guard”, “Prompt Guard” ve “CyberSecEval” gibi açık kaynak güvenlik araçları geliştirildi. Bu araçlar sayesinde geliştiriciler, modelleri kendi uygulamalarına uygun şekilde güvenli hale getirebiliyor.
Öte yandan Llama 4, model önyargılarını azaltma konusunda da önemli ilerlemeler sağladı. Llama 3.3’e kıyasla tartışmalı sosyal ve politik konularda yanıttan kaçınma oranı %7’den %2’nin altına indirildi. Sorulara yanıt verirken taraf tutma oranı ise %1’in altına çekildi. Model artık tartışmalı konularda daha dengeli ve çok yönlü yanıtlar verebiliyor.
Kullanıma çoktan açıldı
Llama 4 modelleri, Meta’nın yapay zeka konusundaki en ileri adımlarını temsil ediyor. WhatsApp, Messenger, Instagram Direct ve Meta.AI üzerinden bu modelleri deneyimlemek mümkün. Ayrıca geliştiriciler, modelleri llama.com ve Hugging Face üzerinden indirip kullanabiliyor.
Meta, açık kaynak yaklaşımıyla bu teknolojileri daha geniş bir geliştirici kitlesine ulaştırmayı hedefliyor ve gelecekte LlamaCon etkinliğinde bu vizyonu daha detaylı olarak paylaşmayı planlıyor.
Görsel kaynaklar: Meta.


